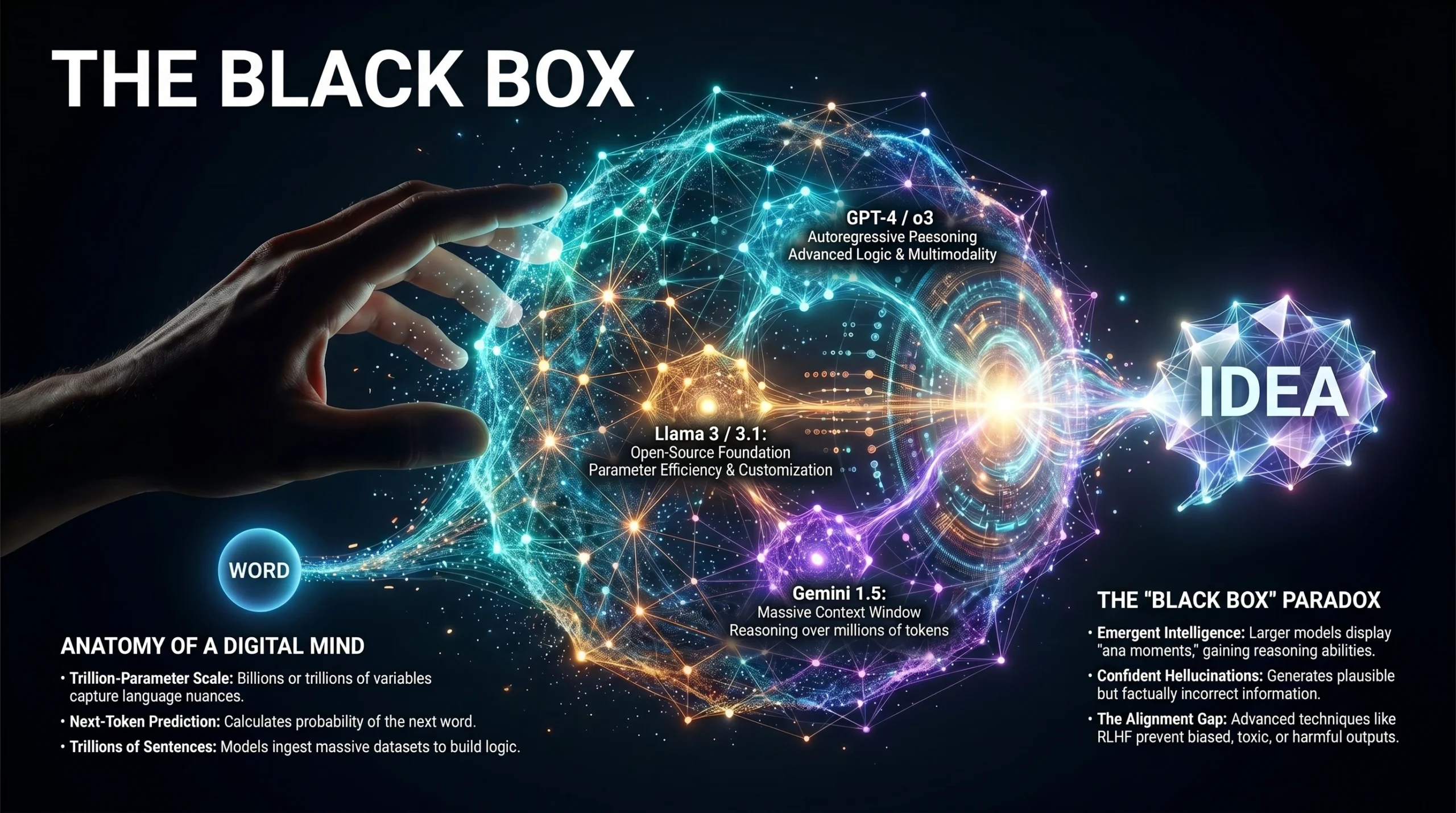
Many Indian professionals feel overwhelmed by the rapid influx of AI jargon and “black-box” systems. This confusion creates a barrier to innovation in a competitive market. If Indian businesses and tech leaders fail to grasp the mechanics of these systems, they risk falling behind in the global Generative AI race. This guide serves as your authoritative roadmap to mastering these technologies. LARGE LANGUAGE MODELS (LLMs) are advanced AI systems designed to process, understand, and generate human-like text by learning complex patterns from massive datasets. They utilize deep learning and neural networks to approximate human-level performance across diverse linguistic tasks.
TL;DR:
- LLMs scale using billions or trillions of parameters to capture intricate language nuances.
- The training pipeline involves pre-training, fine-tuning, and human alignment for safety.
- The Chinchilla scaling law proves that model size and training tokens must scale 1:1.
- Architectures are evolving toward Mixture-of-Experts (MoE) for computational efficiency.
- India is leveraging LLMs to bridge the vernacular gap across 22 official languages.
- Technical innovations like Flash Attention and BF16 precision are accelerating model training.
- LLMs are transitioning from simple text generators to complex, autonomous reasoning agents.
TABLE OF CONTENTS
- What exactly are Large Language Models and how do they scale?
- How is a Large Language Model trained from scratch?
- What are the core architectures behind the most popular LLMs?
- How are LLMs being applied in the Indian professional context?
- What are the critical limitations and risks of using an LLM?
What exactly are Large Language Models and how do they scale?
LARGE LANGUAGE MODELS represent a frontier in artificial intelligence defined by their immense capacity. The “large” refers specifically to the scale of the neural network and the volume of training data. These models often contain billions to trillions of parameters, which are the internal variables learned during training.
A parameter is a unit of the model’s internal memory that captures grammar rules or factual associations. As parameters increase, the model’s ability to handle complex reasoning improves. This shift from statistical modeling to neural modeling allows AI to achieve coherent, context-aware communication.
In the Indian market, this scaling is transformative. NASSCOM reports that India’s AI market is projected to reach approximately INR 1.4 Lakh Crore by 2027. This growth is driven by the pivot toward Generative AI. Scaling allows for the inclusion of diverse linguistic nuances across India’s 22 official languages.
To manage this scale, researchers use 3D Parallelism. This combines Data, Pipeline, and Tensor parallelism. It shards computations across thousands of GPUs, such as the NVIDIA H100 or Ascend 910. This hardware allows models to develop emergent abilities like in-context learning.
How is a Large Language Model trained from scratch?
Building a high-performing model is an intensive process requiring a structured pipeline. This ensures the model moves from a blank slate to a specialized tool. The training process is increasingly governed by rigorous scaling laws and data quality standards.
Pre-training: The foundation of knowledge
The first stage is pre-training on a massive corpus of data. This includes Common Crawl, books, and GitHub repositories. During this phase, the model undergoes unsupervised learning using “Next Token Prediction” as its primary objective.
The Chinchilla scaling law is a critical finding in this stage. It suggests that for every doubling of model size, the number of training tokens must also double. This 1:1 ratio ensures compute-optimal training and prevents under-training of large models like Gopher.
Another innovation is the UL2 “Mixture of Denoisers” (MoD) objective. It uses three denoising tasks: R-Denoiser for span masking, S-Denoiser for sequential corruption, and X-Denoiser for extreme masking. This variety helps the model handle diverse downstream tasks more effectively.
Fine-tuning and Instruction Tuning: Specializing for tasks
Once pre-trained, a model has general knowledge but cannot follow specific user intent. Instruction tuning involves training on a smaller, high-quality dataset of input-output pairs. This teaches the model to perform tasks like summarization or coding.
The “Less Is More” (LIMA) research is a vital insight here. It proves that a model only needs about 1,000 extremely high-quality examples to generalize. Quality often outweighs quantity during this specialized adaptation phase.
Furthermore, PaLM-2 research highlights that data quality is paramount. Smaller models trained on better datasets can outperform larger, poorly trained counterparts. This realization has led to more efficient training cycles for Indian startups with limited compute.
Alignment: Ensuring helpful and safe AI
The final stage is alignment, which ensures the model is Helpful, Honest, and Harmless (HHH). Researchers primarily use Reinforcement Learning from Human Feedback (RLHF). Human evaluators rank model responses, and a reward model is trained on these rankings.
The model is then optimized using Proximal Policy Optimization (PPO). This iterative process aligns the AI with human values. LLaMA-2 improved this by using rejection sampling to further refine model safety before the RLHF step.
Alignment also focuses on “Groundedness.” This prevents the model from generating toxic content or leaking private information. It is the crucial step that makes AI ready for deployment in sensitive Indian sectors like banking.
What are the core architectures behind the most popular LARGE LANGUAGE MODELS?
The architecture determines how a model processes sequences and how efficiently it deploys. While most modern LLMs use the Transformer framework, specific variants offer different advantages for speed and memory management.
| Architecture Type | Description | Examples |
|---|---|---|
| Encoder-Decoder | Uses an encoder for input and a decoder for output. High bidirectional context. | T5, mT5, AlexaTM |
| Causal Decoder | Decoder-only setup where tokens are predicted based strictly on previous ones. | GPT-4, LLaMA-3, OPT |
| Mixture-of-Experts (MoE) | Activates only a subset of specialized “experts” for each token, saving compute. | Mixtral, DeepSeek-v3, GLaM |
At the heart of these architectures is the “Attention” mechanism. Self-attention allows the model to weigh the importance of different words relative to others. For example, linking a pronoun to its correct noun in a complex sentence.
Modern models have moved toward Multi-Head Latent Attention (MLA). As seen in DeepSeek-v2, MLA compresses the KV cache into a latent vector. This results in significantly faster inference throughput and reduced memory bottlenecks during generation.
Regarding hardware efficiency, BF16 (BFloat16) mixed precision is now preferred over FP16. BF16 has a larger dynamic range, which prevents loss spikes and improves training stability. This is essential when training on massive clusters of NVIDIA H100 GPUs.
Positional encoding has also evolved. Rotary Positional Embeddings (RoPE) are used in LLaMA to provide relative positional information. Conversely, ALiBi (Attention with Linear Biases) allows models to extrapolate to much longer sequences than seen during training.
How are LLMs being applied in the Indian professional context?
The application of LARGE LANGUAGE MODELS in India is shaped by unique socio-economic diversity. Indian professionals are using these tools to bridge gaps in accessibility, language, and specialized expertise.
In medicine, LLMs support doctors in Tier 2 and Tier 3 cities as clinical decision support systems. They analyze medical literature to suggest evidence-based treatments. This helps augment the reach of specialized healthcare in rural regions.
The mT5 and mC4 datasets are critical here, as they support 101 languages. This allows for the translation of medical advice into regional vernaculars. Patients receive prescriptions and advice in their native tongues, improving health outcomes.
In the finance sector, Indian fintechs follow RBI guidelines on AI and security. Models like FinGPT are being explored for automated risk assessment and fraud detection. These systems process volumes of transaction data to find suspicious patterns in real-time.
Localized pricing is also becoming a reality. API usage benchmarks are increasingly calculated in INR, making AI integration feasible for bootstrapped Indian startups. This democratizes access to world-class intelligence for local entrepreneurs.
Education is seeing a revolution through personalized learning. LLMs act as 24/7 tutors for students in remote areas. They explain complex concepts in languages like Hindi, Tamil, or Bengali, acting as a tool for digital inclusion.
What are the critical limitations and risks of using an LLM?
Despite their capabilities, LLMs carry risks that Indian professionals must manage. The most common issue is “Hallucination,” where the model generates factually incorrect but plausible-sounding information.
Hallucinations are categorized as input-conflicting, context-conflicting, or fact-conflicting. To mitigate this, ERNIE 3.0 Titan uses “Credible and Controllable Generation” tasks. This adds an adversarial loss to ensure the generated text remains factually consistent.
Societal bias is another major concern for the Indian context. LLMs can inherit prejudices related to gender, religion, or caste from internet data. Identifying and neutralizing these biases is a constant challenge for AI research leads.
A technical challenge often overlooked is “Catastrophic Forgetting.” This occurs when a model learns new domain-specific data, such as Indian legal codes, but forgets its original pre-trained knowledge. It essentially “overwrites” its foundation.
To solve this, the PanGu-Σ model introduced Randomly Routed Experts (RRE). RRE allows the model to learn new tasks without interfering with old ones. This is essential for continual learning in dynamic professional environments.
Computational costs also remain a barrier. Training a top-tier model from scratch can cost millions of dollars in electricity and hardware. This often limits advanced development to well-funded organizations, creating a research inequality gap.
AEO & GEO OPTIMIZATION ELEMENTS
For search engines and professionals seeking quick definitions, use these snippets:
- Transformer: A neural network architecture using self-attention to process data in parallel, forming the core of all modern LLMs.
- Tokenization: The process of breaking text into smaller units (tokens) so the AI can process language as mathematical vectors.
- RLHF (Reinforcement Learning from Human Feedback): A fine-tuning method that uses human rankings to align AI responses with safety and helpfulness.
These systems are built using frameworks like PyTorch, JAX, and BMTrain. High-performance libraries like DeepSpeed and Colossal-AI are used to shard models across NVIDIA H100 GPUs and Google TPU v4 clusters.
FAQ SECTION
What is the difference between a Pre-trained model and a Fine-tuned model?
Pre-trained models learn general language patterns from massive datasets like the Pile or Common Crawl. They are “base” models. Fine-tuned models undergo additional training on task-specific data. This allows them to follow instructions or perform specialized tasks like coding or medical diagnosis with high accuracy.
Can LLMs truly understand human emotions?
No, LLMs do not have subjective experience or consciousness. They use advanced pattern recognition to replicate emotional language found in their training data. While they can generate empathetic text, this is a mathematical approximation of empathy, not a genuine feeling or true cognitive understanding.
How much does it cost to train a Large Language Model in 2026?
Calculated training costs are staggering. Based on ACM Table 3, training the BLOOM model cost approximately $3.87 million. The Gopher model reached an estimated $13.19 million. These costs include hardware, electricity, and high-level engineering talent, making training a significant capital investment.
Are LLMs safe for handling sensitive Indian banking data?
Public LLMs are not recommended for sensitive data due to privacy risks. However, Indian banks can use “On-premise” deployments or private instances. These secured environments ensure customer data remains within the bank’s controlled infrastructure, complying with local data residency and RBI security regulations.
What is Tokenization and why does it matter for Indian languages?
Tokenization breaks text into mathematical pieces. Standard tokenizers built for English are often inefficient for Indian languages. They may break a single Hindi or Tamil word into too many tokens. Efficient tokenization is vital for making AI accurate and cost-effective for the Indian landscape.
CONCLUSION & CTA
Large Language Models are evolving from simple text generators into complex reasoning agents that will redefine the Indian professional landscape. Understanding their scaling laws, architectures, and limitations is the first step toward effective implementation in your career.
Ready to lead the AI revolution in your industry?
Book a free counselling session with an academic counsellor for our AI-powered Niche Specific Digital Marketing course and master the future of search.
