Many Indian startups find their AI agents breaking in production. They work during internal demos but hallucinate when users reference past conversations. This happens because the model loses the signal required for a coherent response.
Lost-in-the-Middle issues and quadratic compute costs make large context windows a massive liability. For developers in Bengaluru and beyond, simply expanding the window is like pouring water into a leaky bucket.
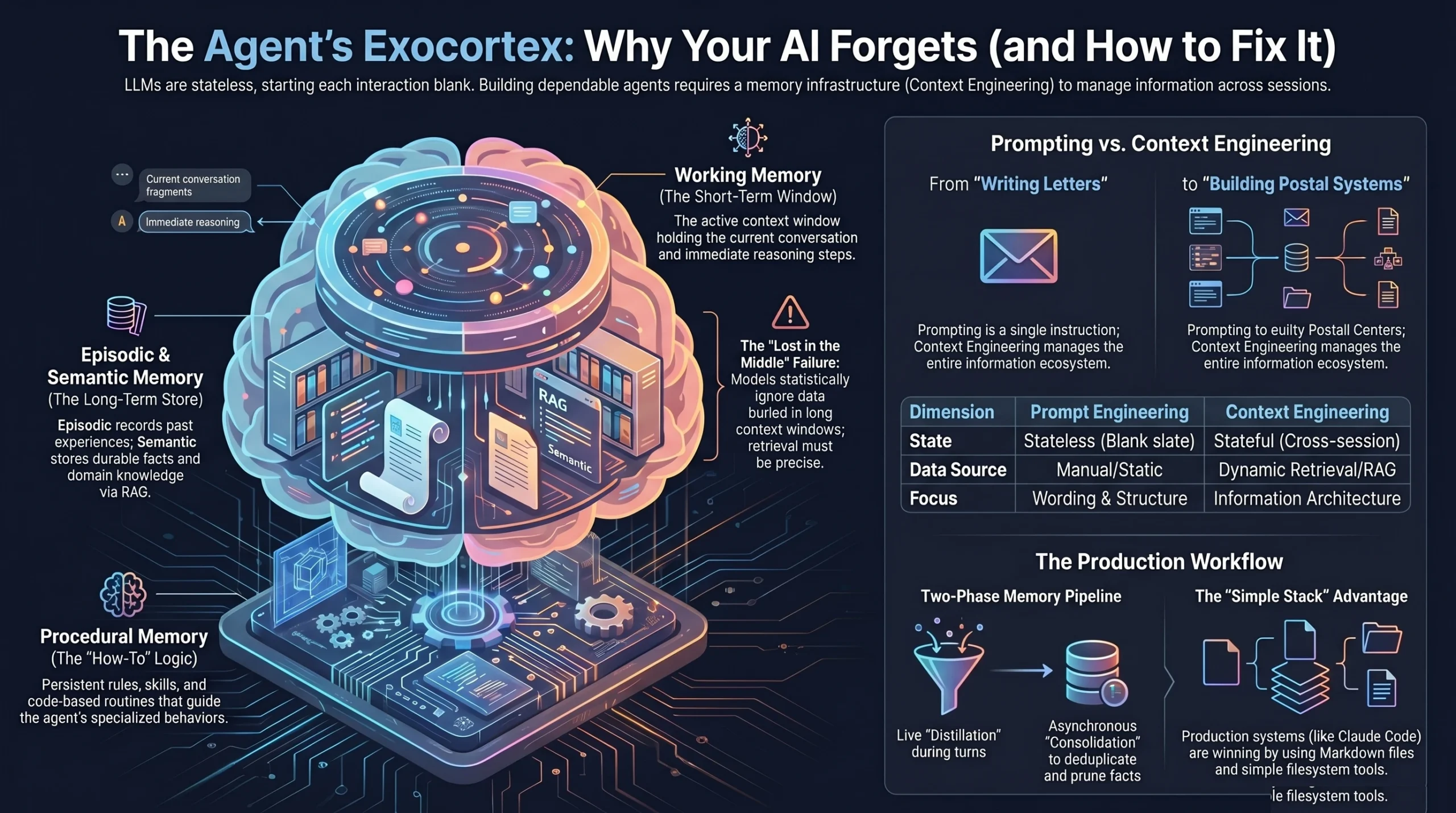
Memory Engineering is the systematic curation of an AI model’s entire inference environment. It manages the full information stack including system instructions, memory, retrieved knowledge, tool outputs, and user profiles to ensure production reliability.
TL;DR
- Context engineering manages the full information stack: memory, history, and tools.
- Transformer attention is quadratic: doubling context windows quadruples your compute costs.
- Contextual retrieval reduces retrieval failures by 49 percent compared to raw chunking.
- Agentic RAG improves the faithfulness metric by 42 percent via self-reflection.
- Supermemory achieves sub-300ms recall speeds with 85.4 percent accuracy on LongMemEval-S.
- Systematic context management prevents 30 percent of information loss in long windows.
Table of Contents
- What is Memory Engineering and why is it replacing Prompt Engineering?
- Why are your 1M+ token context windows burning your budget?
- How does the 3-generation RAG evolution impact production AI?
- What are the three layers of enterprise AI memory?
- Why is Supermemory outperforming Zep and Mem0 in speed benchmarks?
- Can a simple folder system replace complex agent infrastructure?
- How should Indian enterprises manage context costs in 2026?
- FAQ Section
What is Memory Engineering and why is it replacing Prompt Engineering?
Prompt engineering focuses on the wording of a single input. Context engineering is the superset that orchestrates the entire inference environment. If prompt engineering is writing a good letter, context engineering is building the postal system.
“Context engineering is the delicate art and science of filling the context window with just the right information for the next step.” — Andrej Karpathy
Bengaluru-based developers are moving beyond simple “wrapper” apps to sophisticated state management. This shift ensures that agents remain reliable across multi-session interactions instead of resetting after every turn.
| Dimension | Prompt Engineering | Context Engineering |
|---|---|---|
| Scope | Single input and output | Full inference lifecycle |
| State | Stateless | Stateful across sessions |
| Data Sources | Manual and written | Retrieved on the fly |
| Scalability | Rarely scales in production | High enterprise scalability |
Why are your 1M+ token context windows burning your budget?
Ultra-long context windows are not a silver bullet for production AI. Transformer attention is quadratic: doubling the context quadruples your compute requirements. This leads to “Context Rot” where noise eventually overwhelms the signal.
Research confirms that LLMs perform worst on information buried in the middle of long contexts. Anthropic suggests placing critical information at the beginning or end of the window to avoid this “attention blind spot.”
A million-token window does not fix a broken retrieval strategy: it only delays failure. Systematic context orchestration can prevent 30 percent of information loss, saving both your budget and your accuracy.
How does the 3-generation RAG evolution impact production AI?
Retrieval-Augmented Generation (RAG) has moved from linear pipelines to active agents. Agentic RAG upgrades the process into an architecture with planning and self-correction. This improves the faithfulness metric by 42 percent.
Anthropic research indicates that contextual retrieval cuts failures by 49 percent. By adding chunk-specific summaries before the embedding process, the system preserves the meaning of orphaned sentences.
| Dimension | Naive RAG | Advanced RAG | Agentic RAG |
|---|---|---|---|
| Retrieval Strategy | Fixed top-k vector | Hybrid and re-ranking | Dynamic and autonomous |
| Typical Accuracy | 60 to 70 percent | 75 to 85 percent | 85 to 95 percent |
| Quality Control | No validation | Relevance filtering | Self-reflection (Reflexion) |
What are the three layers of enterprise AI memory?
The cognitive-science-inspired architecture from the Park et al. 2023 study defines three distinct layers for agents.
Working Memory
This represents the current conversation state. It includes recent messages, tool outputs, and retrieved facts. It is the most precise but also the most expensive form of context.
Episodic Memory
This stores experiences from past interactions, such as previous errors or specific user preferences. The Reflexion framework allows agents to learn from failures stored here to avoid repeating mistakes.
Semantic Memory
This is the stable knowledge base of the enterprise. For an Indian e-commerce brand like Myntra, this layer holds the return policies and domain-specific logistics rules that never change.
Why is Supermemory outperforming Zep and Mem0 in speed benchmarks?
Supermemory provides sub-300ms context retrieval, which is critical for real-time agents. In comparison, Zep typically runs at 4 seconds and Mem0 takes 7 to 8 seconds. This speed gap is vital for production traffic.
The system achieves 85.4 percent accuracy on LongMemEval-S. It utilizes a five-layer stack: Connectors, Extractors, Super-RAG, Memory Graph, and User Profiles. This tracks relationships between facts rather than just similarity scores.
Super-RAG combines hybrid search with context-aware reranking. This ensures that personalization lives in the user profile layer, providing high precision across massive, growing datasets.
Can a simple folder system replace complex agent infrastructure?
The “Folder as a Workspace” methodology offers a low-code alternative to heavy Python frameworks. This approach suits cost-sensitive Indian boutiques that require transparency over “black box” agentic codebases.
- The Map (Claude.md): A floor plan that defines the agent’s naming conventions and folder structures.
- The Task Rooms: Dedicated directories for specific stages like writing, research, or coding.
- The Workspace: The actual file system where the agent stores and edits drafts.
This structure follows a four-stage production pipeline: Brief, Spec, Build, and Output. By using Markdown files as context, the agent knows where to find information without reading every file in the directory.
How should Indian enterprises manage context costs in 2026?
Pricing for models like GPT-5 mini has reached 25 cents per 1 million tokens. Tier 1 global-facing SaaS companies in India often prioritize maximum accuracy over latency.
Tier 2 localized services focus on extreme cost-effectiveness. These enterprises are opting for “Context Compression” to survive high-volume production. This distills long documents into key passages to stay within tight token budgets.
RAG remains the superior choice for precise source tracking. Since inference latency for 2 million tokens can reach 60 seconds, RAG architecture is still the standard for real-time, localized Indian applications.
Memory Engineering Definition: The practice of curating every piece of information an AI sees at inference time. It manages memory, retrieved documents, history, and user profiles to ensure production reliability.
Entity Density: This document leverages technologies like LlamaIndex, LangChain, and Pinecone. It compares vector databases such as Milvus and Qdrant while highlighting Supermemory for high-speed state management.
FAQ Section
What is the difference between RAG and Context Engineering?
RAG is a technical retrieval component. Context Engineering is the broader methodology of orchestrating the entire information flow, including memory, tools, and history.
How do I fix ‘Lost in the Middle’ errors?
Place the most critical information at the beginning or end of the context window. Use re-ranking and hierarchical context structures to prevent the model from ignoring the middle.
Why is sub-300ms retrieval critical for AI agents?
Retrieval over 1 second creates noticeable lag in agent responses. Sub-300ms speeds ensure the AI feels interactive and responsive to real-world user traffic and high query volumes.
Is a 2-million token window enough to replace RAG?
No. Costs increase non-linearly and inference latency is too high for real-time needs. RAG remains essential for precise source attribution and managing massive datasets effectively.
Which Vector DB is best for Indian startups: Pinecone or Milvus?
Pinecone is best for mid-sized projects needing zero operational overhead. Milvus is superior for massive data volumes and extreme performance requirements at a larger scale.
Conclusion
Context determines the upper bound of intelligence for any AI system. Transitioning from simple prompts to engineered memory is the only way to build enterprise-grade, reliable agents.
Take the next step in your AI journey. Book a free counselling session with an academic counsellor for our AI-powered Niche Specific Digital Marketing course to master high-performance content strategies.
Book a Free Counselling Session