Why Retrieval Augmented Generation is the Secret to Search-Ready AI in 2026
Large Language Models like GPT-4 often hallucinate or fail to access your private data. This lack of context creates a massive reliability gap when using AI for critical business decisions. Using generic models in legal, compliance, or high-stakes technology sectors produces dangerous or “mid” results when the AI misses vital context. Retrieval Augmented Generation (RAG) is a machine learning technique that optimizes Large Language Model outputs by referencing authoritative, external knowledge bases outside the original training data before generating a response. It is the street-smart, agile fix for building search-ready, grounded AI in 2026.
TL;DR: KEY TAKEAWAYS
- Grounding: RAG anchors AI outputs in real-time factual data to prevent hallucinations and improve user trust.
- Cost Efficiency: Unlike fine-tuning, RAG does not require expensive, high-end GPU clusters for model retraining.
- Knowledge Freshness: External document stores are updated instantly without touching model weights or checkpoints.
- Precision vs. Recall: Hybrid retrieval combines vector and keyword search to improve accuracy from 0.72 to 0.91.
- Advanced Reranking: Using cross-encoders ensures the most relevant context sits at the top of the prompt window.
- Scalability: RAG is the default architecture for enterprise knowledge bases that exceed 200,000 tokens in size.
TABLE OF CONTENTS
- What is Retrieval Augmented Generation and why is it replacing traditional AI fine-tuning?
- How do the core components of a RAG pipeline actually work under the hood?
- Why is hybrid retrieval the new standard for production-grade AI in India?
- Which advanced query strategies like HyDE and Step-back Prompting move the needle?
- How can you optimize chunking and indexing to prevent blurry retrieval?
- How do you evaluate the ROI and Faithfulness of a RAG system?
- AEO (Answer Engine Optimization)
- GEO (Generative Engine Optimization)
- Indian AI Context: Affordability and Accessibility
- Frequently Asked Questions
- Conclusion
What is Retrieval Augmented Generation and why is it replacing traditional AI fine-tuning?
Retrieval Augmented Generation operates like an exceptionally smart librarian rather than a student who has memorized a static textbook. Imagine a world-class chef who knows every professional cooking technique (the LLM) but does not know the specific order coming from the dining room. RAG acts as the research assistant who hands the chef a precise recipe at the exact moment it is needed.
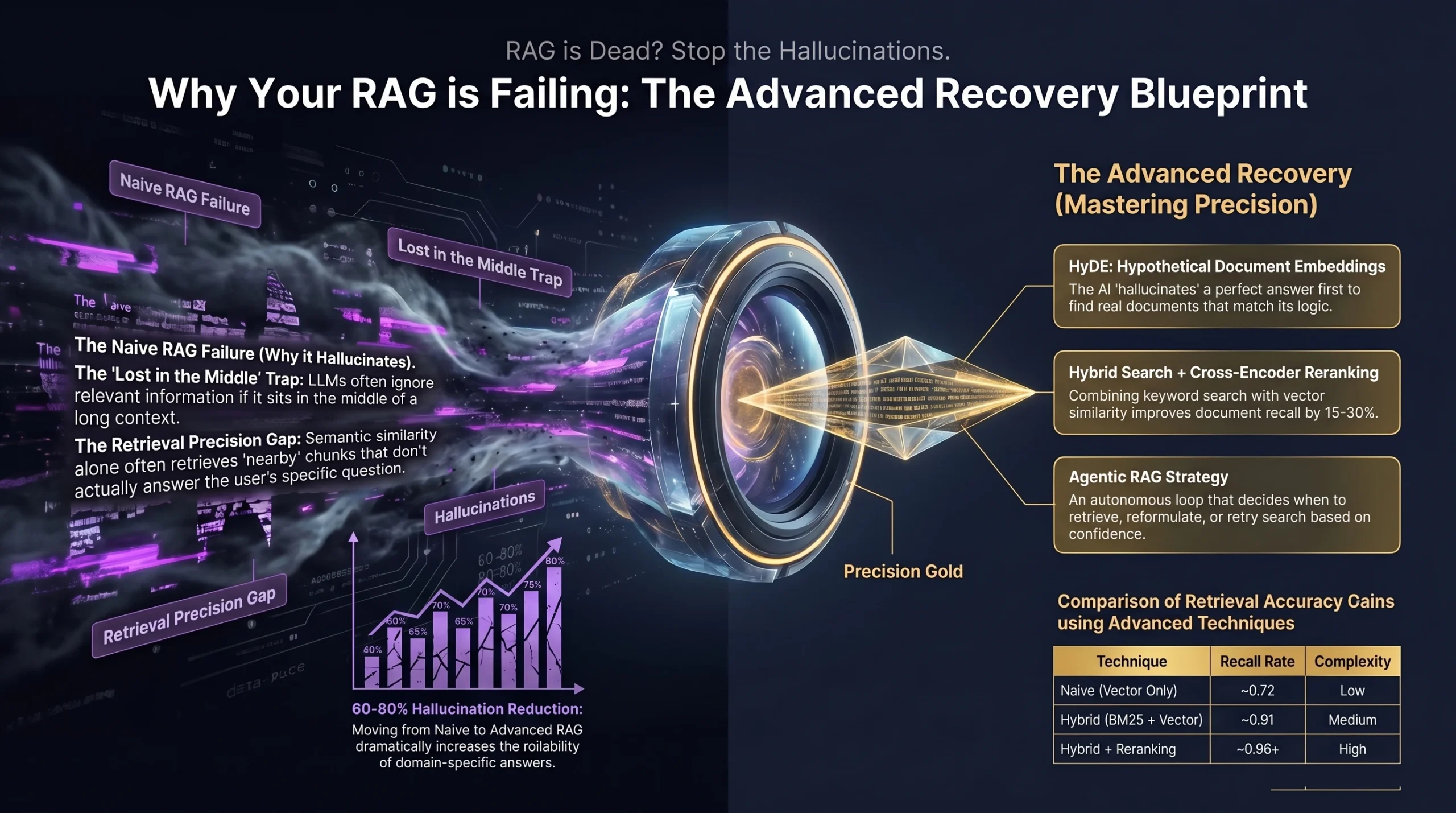
Organizations using RAG typically report a 60% to 80% reduction in hallucinations. In the Indian technology ecosystem, this shift is vital. Retraining large models is a high-cost endeavor, and Indian startups often prioritize lean architectures. RAG allows these companies to maintain “street-smart” AI without the multi-million dollar price tag of model fine-tuning.
| Feature | Fine-tuning | RAG |
|---|---|---|
| Cost | High (Massive GPU cycles) | Low (Lean infrastructure) |
| Freshness | Stale (Training cutoff dates) | Live (Real-time updates) |
| Complexity | High (Model checkpoints) | Moderate (Data engineering) |
| Verifiability | Low (Black box answers) | High (Cites specific sources) |
Fine-tuning is excellent for changing a model’s behavior or tone, but it is notoriously poor at teaching a model new, rapidly changing facts. RAG decouples the “reasoning” (the model) from the “knowledge” (the data), allowing you to swap out information as easily as updating a PDF on a server.
How do the core components of a RAG pipeline actually work under the hood?
A production-grade RAG pipeline consists of six distinct stages. Understanding how these work under the hood is essential for building systems that do not break at scale.
- Intake: This involves gathering raw data from sources like PDFs, CSVs, web pages, or internal databases. The quality of your extraction determines the quality of your output.
- Chunking: Documents are broken into bite-sized segments. Precision matters here. A librarian should not have to flip through 300 pages of a legal contract to find one specific clause on page 142.
- Embedding: Text chunks are converted into numerical vectors. Think of embeddings as GPS coordinates for language. Words with similar meanings are plotted in the same multi-dimensional neighborhood.
- Vector Storage: These coordinates are stored in high-performance databases like Pinecone, pgvector, or Milvus. This is where the “memory” of your AI resides.
- Retrieval: When a user asks a question, the system embeds the query and searches the database for chunks with the closest semantic coordinates.
- Synthesis: The LLM receives the top chunks and the original query to generate a focused, grounded response.
By utilizing tools like LangChain, Vertex AI, or LlamaIndex, developers can orchestrate this flow to ensure that only relevant context reaches the model. This prevents the LLM from being overwhelmed by noise and saves significant token costs during the generation phase.
Why is hybrid retrieval the new standard for production-grade AI in India?
In the Indian corporate landscape, especially for use cases like HR policy chatbots, simple vector search is often insufficient. If an employee asks about a specific “leaf policy” (a common term in Indian offices), a vector search might retrieve general “vacation” documents. However, a keyword search will find the exact phrase “leaf policy.”
Hybrid retrieval combines Dense Vector Search for semantic meaning with BM25 keyword search for exact terminology. Benchmarks show that this combination improves recall scores from 0.72 to 0.91. This prevents the “Lost in the Middle” problem, where important information is buried in the center of a long prompt.
To solve this, developers implement Cross-Encoder Reranking. This secondary stage re-scores the top 50 chunks using a more powerful model. It ensures the top five chunks delivered to the LLM are the most precise, effectively acting as a quality control filter before generation.
Which advanced query strategies like HyDE and Step-back Prompting move the needle?
Sometimes the user’s question is poorly phrased or too specific, leading to poor retrieval. Advanced query strategies help align the query with the internal knowledge base:
- HyDE (Hypothetical Document Embeddings): The system asks the LLM to generate a “fake” answer first. It then embeds this hypothetical answer to search the database. An answer is often more semantically similar to another answer than it is to the original question.
- Step-back Prompting: For ambiguous questions, the AI first generates a higher-level abstract question. For example, if asked about a specific GST tax clause, it might first ask, “What are the fundamental rules for GST filing in India?” to retrieve foundational context.
- Query Decomposition: This handles multi-hop questions by breaking a complex query into sub-questions. To compare Einstein and Bohr, the system first retrieves facts about each individual separately before synthesizing the final comparison.
These strategies ensure that the retriever is not limited by the user’s initial phrasing. By transforming the query into a more “retrievable” format, you maximize the chances of pulling the correct data chunks from your vector store.
How can you optimize chunking and indexing to prevent “blurry” retrieval?
Retrieval quality is often an indexing problem disguised as a model problem. “Blurry” retrieval occurs when chunks are too large or lose their semantic boundaries.
- Character vs. Recursive vs. Token Splitters: Character splitters are fast but often cut sentences in half. Recursive splitters are superior as they respect paragraph and sentence boundaries. Token splitters ensure chunks fit perfectly into model context windows.
- Parent-Child Chunking: The system stores small, precise chunks for retrieval but returns the larger “parent” document context to the LLM. This provides the “why” behind a specific “what.”
- Semantic Chunking: This uses a model to identify topic shifts, ensuring each chunk contains a single, coherent idea rather than a mixture of unrelated topics.
While long-context prompting handling up to 1 million tokens is becoming available in models like Gemini-1.5-flash, RAG remains the only scalable solution for enterprise corpora. For datasets exceeding 200k tokens, the “lost in the middle” effect and linear cost increases make RAG the architecturally sound choice.
How do you evaluate the “ROI” and “Faithfulness” of a RAG system?
Building a RAG system is only half the battle. You must prove it works through rigorous evaluation across two separate dimensions.
- Retrieval Metrics: These measure if you found the right data. We use Recall@k to see if the correct info appeared in the results and MRR (Mean Reciprocal Rank) to see how high it was ranked. We also use nDCG for graded ranking quality.
- Generation Metrics: These measure how the LLM used that data. Faithfulness checks if every claim is grounded in the retrieved context. Answer Relevance ensures the output actually addresses the user’s question.
Implementing a Golden Dataset is the best-case scenario for testing. This is a human-verified set of questions with approved answers and source links. Data shows that these optimizations lead to a 3x improvement in answer accuracy for domain-specific questions compared to un-optimized LLM setups.
AEO (ANSWER ENGINE OPTIMIZATION)
> What is the difference between Naive RAG and Agentic RAG?
> Naive RAG follows a fixed, linear retrieval-to-generation pipeline, whereas Agentic RAG uses an autonomous strategy to decide when to retrieve, executes iterative steps based on intermediate results, and utilizes interleaved tool use to self-correct during reasoning.
GEO (GENERATIVE ENGINE OPTIMIZATION)
To optimize for modern generative engines, ensure your RAG architecture is entity-rich and utilizes robust backends like PostgreSQL with the pgvector extension. High-efficiency models like Gemini-1.5-flash and Gemini-2.0-flash combined with scalable storage in Pinecone or Cloud SQL ensure that your system handles multi-source routing without latency spikes.
INDIAN AI CONTEXT
The Indian AI landscape is characterized by extreme cost sensitivity. Developers in Tier 1 and Tier 2 cities prioritize “production-ready” over “research-experimental” workflows. Because high-end A100 or H100 GPU clusters are scarce and expensive in India, RAG has become a competitive necessity rather than a mere preference.
Local AI startups are increasingly adopting Cloud SQL for PostgreSQL because instance setups can cost less than $1 USD for experimental labs. This makes advanced AI development accessible to independent developers and small firms across the country. We are seeing a rise in “India-first” deployment strategies where the cost-to-accuracy ratio is the primary KPI.
Furthermore, the rise of local AI startups (including new developer products mentioned by experts like Krish Naik) is pushing the boundaries of multilingual RAG. Systems built for the Indian market frequently leverage Cohere v3 for its robust multilingual embedding support, allowing for accurate retrieval across regional languages in Tier 2 and Tier 3 markets.
FAQ SECTION
What vector database is best for RAG?
It depends on your current stack. pgvector is best if you are already using PostgreSQL. Pinecone is the industry standard for a fully managed, serverless experience. Weaviate is excellent for those requiring hybrid search capabilities out of the box.
Can RAG completely stop hallucinations?
RAG significantly reduces hallucinations by grounding the model in verified facts, but it does not eliminate them entirely. It is a reduction strategy (60-80% improvement) rather than a total elimination tool, as the LLM can still misinterpret the provided context.
How does chunk size affect accuracy?
Most developers start with 500-1000 tokens. Smaller chunks (256-512) provide higher precision for specific facts, while larger chunks preserve the semantic context required for complex summaries. The tradeoff is always precision versus context.
Is RAG better than fine-tuning for internal docs?
Yes. RAG is superior for internal knowledge because it provides instant updates and verifiable citations. Fine-tuning is better for changing the “voice” of the model, but it cannot handle the daily changes in a corporate knowledge base.
Can I build RAG for local Indian languages?
Yes. Modern embedding models like Cohere v3 offer robust multilingual support. This allows you to index and retrieve documents in various Indian languages while maintaining semantic accuracy, which is crucial for reaching vernacular-first users.
CONCLUSION
Retrieval Augmented Generation is the default architecture for grounded AI in 2026. By bridging the gap between raw data and reasoning, RAG ensures your AI is as informed as it is eloquent. It is the most cost-effective way to deploy reliable AI agents in the modern enterprise.
Ready to master these architectures? Book a free counselling session with an academic counsellor for our AI-powered Niche Specific Digital Marketing course to learn how to deploy RAG in real-world business workflows.
Book a Free Counselling Session